Exploring limits to prediction in complex social systems
Abstract
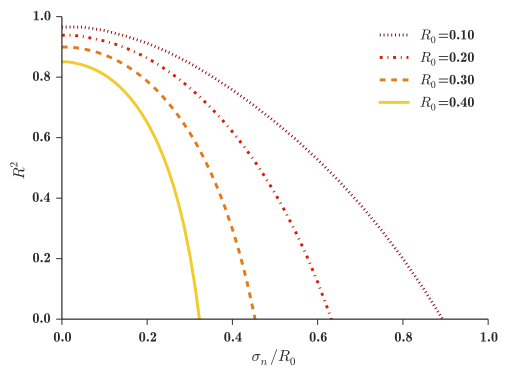
How predictable is success in complex social systems? In spite of a recent profusion of prediction studies that exploit online social and information network data, this question remains unanswered, in part because it has not been adequately specified. In this paper we attempt to clarify the question by presenting a simple stylized model of success that attributes prediction error to one of two generic sources: insufficiency of available data and/or models on the one hand; and inherent unpredictability of complex social systems on the other. We then use this model to motivate an illustrative empirical study of information cascade size prediction on Twitter. Despite an unprecedented volume of information about users, content, and past performance, our best performing models can explain less than half of the variance in cascade sizes. In turn, this result suggests that even with unlimited data predictive performance would be bounded well below deterministic accuracy. Finally, we explore this potential bound theoretically using simulations of a diffusion process on a random scale free network similar to Twitter. We show that although higher predictive power is possible in theory, such performance requires a homogeneous system and perfect ex-ante knowledge of it: even a small degree of uncertainty in estimating product quality or slight variation in quality across products leads to substantially more restrictive bounds on predictability. We conclude that realistic bounds on predictive accuracy are not dissimilar from those we have obtained empirically, and that such bounds for other complex social systems for which data is more difficult to obtain are likely even lower.