Split-door criterion: Identification of causal effects through auxiliary outcomes
Abstract
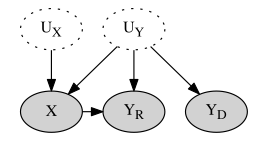
We present a method for estimating causal effects in time series data when fine-grained information about the outcome of interest is available. Specifically, we examine what we call the split-door setting, where the outcome variable can be split into two parts: one that is potentially affected by the cause being studied and another that is independent of it, with both parts sharing the same (unobserved) confounders. We show that under these conditions, the problem of identification reduces to that of testing for independence among observed variables, and propose a method that uses this approach to automatically find subsets of the data that are causally identified. We demonstrate the method by estimating the causal impact of Amazon’s recommender system on traffic to product pages, finding thousands of examples within the dataset that satisfy the split-door criterion. Unlike past studies based on natural experiments that were limited to a single product category, our method applies to a large and representative sample of products viewed on the site. In line with previous work, we find that the widely-used click-through rate (CTR) metric overestimates the causal impact of recommender systems; depending on the product category, we estimate that 50–80% of the traffic attributed to recommender systems would have happened even without any recommendations. We conclude with guidelines for using the split-door criterion as well as a discussion of other contexts where the method can be applied.